Running iOS in QEMU to an interactive bash shell (2): research
*
Edit (July 2020): This project has greatly evolved since its first release. Now, the kernel is patched to bypass the Secure Monitor and the Core Trust mechanisms. We decided to leave this blog post unchanged for educational purposes. To see the current status of the project, please visit our GitHub repository.
This is the second post in a 2-post series about the work I did to boot a non-patched iOS 12.1 kernel on QEMU emulating iPhone 6s plus and getting an interactive bash shell on the emulated iPhone. To see the code and the explanation on how to use it, please refer to the first post. In this post, I will present some of the research that was done in order to make this happen. This research was based on the work done by zhuowei as a starting point. Based on the work done by zhuowei, I already had a way to boot an iOS kernel of a slightly different version on a different iPhone without a secure monitor, while patching the kernel at runtime to make it boot, running the launchd services that preexisted on the ramdisk image and without interactive I/O. In this post I will present:
- How the code was inserted in the QEMU project as a new machine type.
- How the kernel was booted without patching the kernel either at runtime or beforehand.
- How the secure monitor image was loaded and executed in EL3.
- How a new static trust cache was added so self signed executables could be executed.
- How a new launchd item was added for executing an interactive shell instead of the existing services on the ramdisk.
- How full serial I/O was established.
The project is now available at qemu-aleph-git with the required scripts at qemu-scripts-aleph-git.
QEMU code
In order to be able to later rebase the code on more recent versions of QEMU and to add support for other iDevices and iOS versions, I moved all the QEMU code changes into new modules.
I now have the module hw/arm/n66_iphone6splus.c that is the main module for the iPhone 6s plus (n66ap) iDevice in QEMU that is responsible for:
- Define a new machine type.
- Define the memory layout of the UART memory mapped I/O, the loaded kernel, secure monitor, boot args, device tree, trust cache in different exception levels’ memory.
- Define the iDevice’s proprietary registers (currently do nothing and just operate as general purpose registers).
- Define the machine’s capabilities and properties like having EL3 support and start execution in it at the secure monitor entry point.
- Connect the builtin timer interrupt to FIQ.
- Get command-line parameters for defining the files for: kernel image, secure monitor image, device tree, ramdisk, static trust cache, kernel boot args.
The other main module is hw/arm/xnu.c and it is responsible for:
- Loading the device tree into memory and adding the ramdisk and the static trust cache addresses to the device tree where they are actually loaded.
- Loading the ramdisk into memory.
- Loading the static trust cache into memory.
- Loading the kernel image into memory.
- Loading the secure monitor image into memory.
- Loading and setting the kernel and secure monitor boot args.
Booting the kernel with no patches
Basing the work on zhuowei, I already had the ability to boot to user mode with a different iOS version and for a different iPhone while patching the kernel at runtime using the kernel debugger.
The need to patch comes from the fact that after changing the device tree and booting from a ramdisk we encounter a non-returning function waiting for an event that never comes.
By placing breakpoints all over and single stepping in the kernel debugger I found that the non-returning function is IOSecureBSDRoot() which can be found in the XNU code published by Apple in version xnu-4903.221.2:
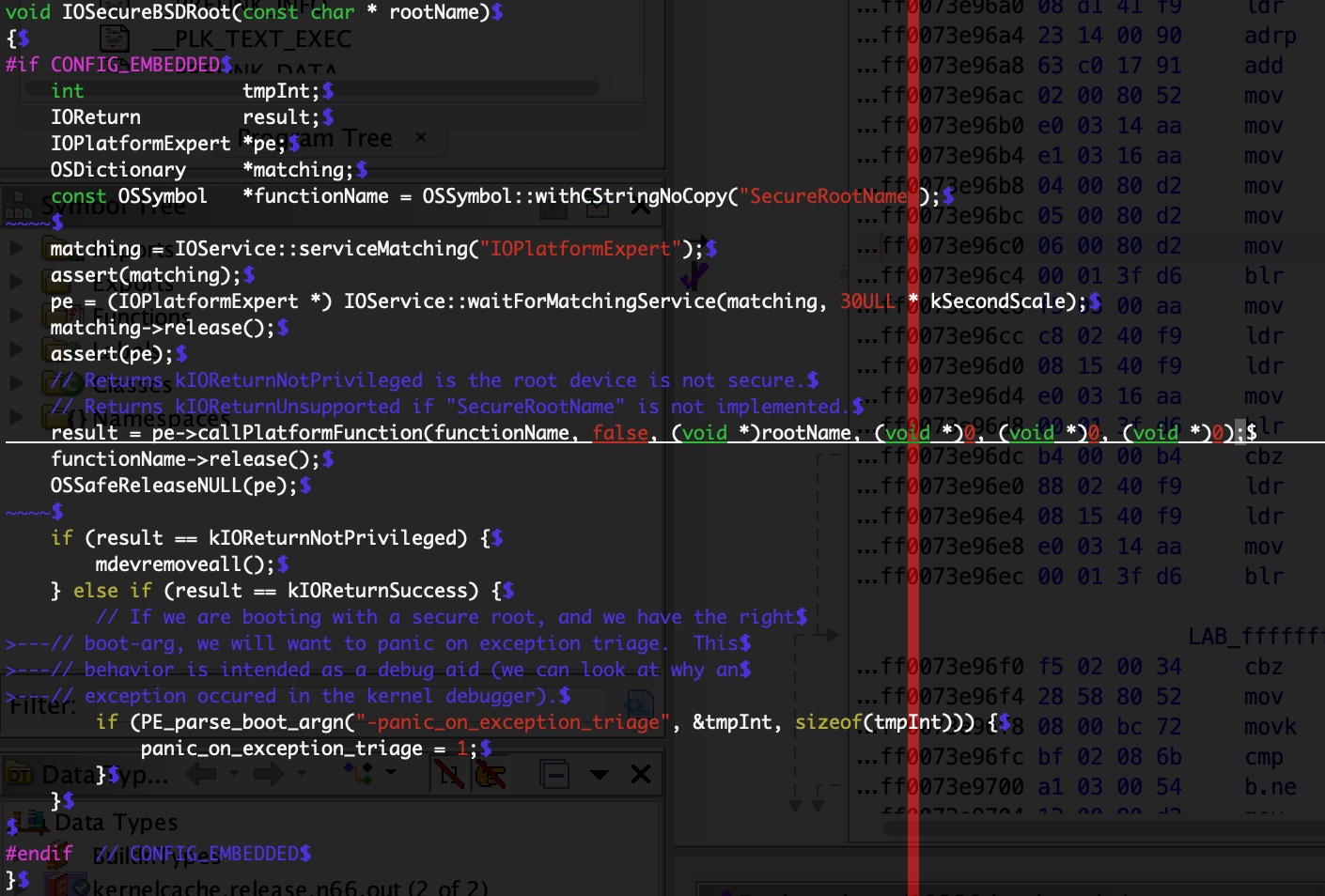
and at runtime, when debugging the kernel itself:
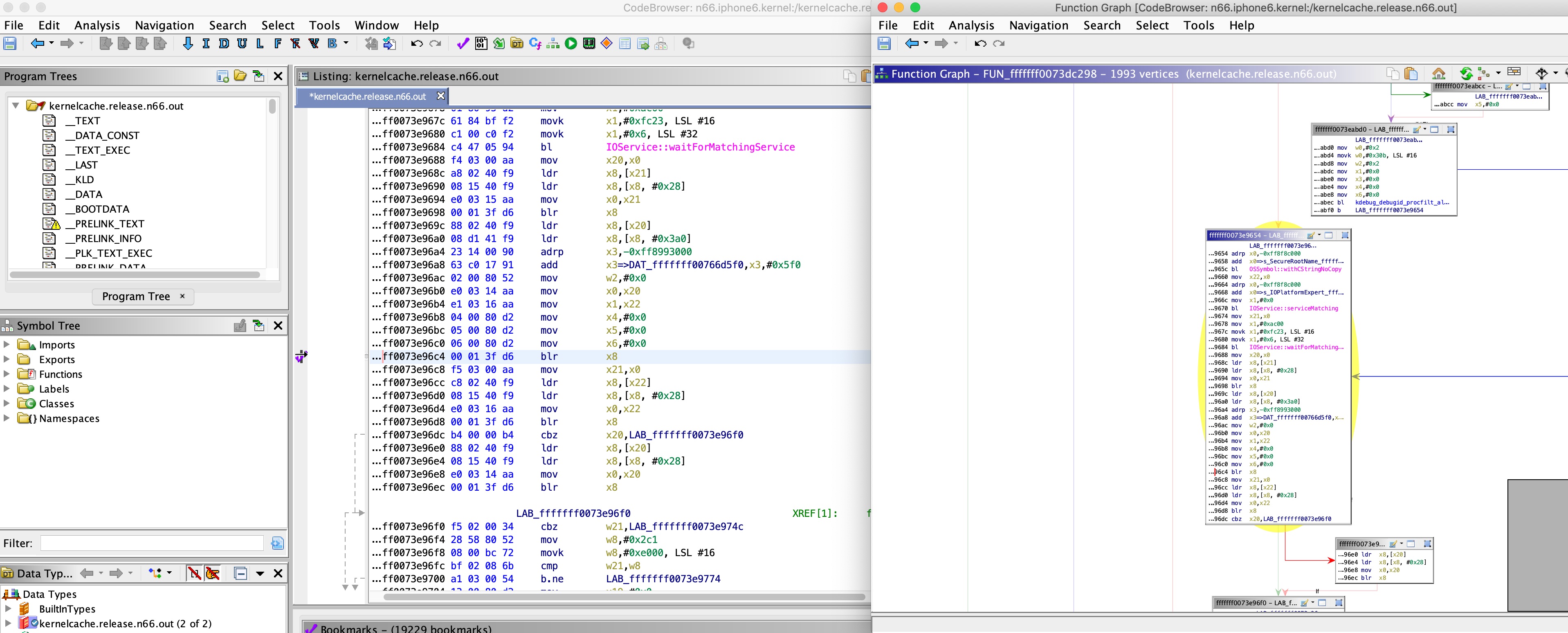
This function doesn’t return, because the call to pe->callPlatformFunction() doesn’t return. For this function I don’t have any reference code, so the kernel is disassembled:

By examining the function, we can see that the non-returning function deals a lot with specific members of the object in x19, and the flow changes depending on these members. I tried a few approaches to understand what these members mean, and where their values are set, but with no luck. These members do seem to be at special offsets, so after a while I tried my luck and used Ghidra to search the whole kernel for functions that use objects and their members at offsets 0x10a, 0x10c and 0x110 - and I got lucky! I found this function, that deals with the exact same object and these members:
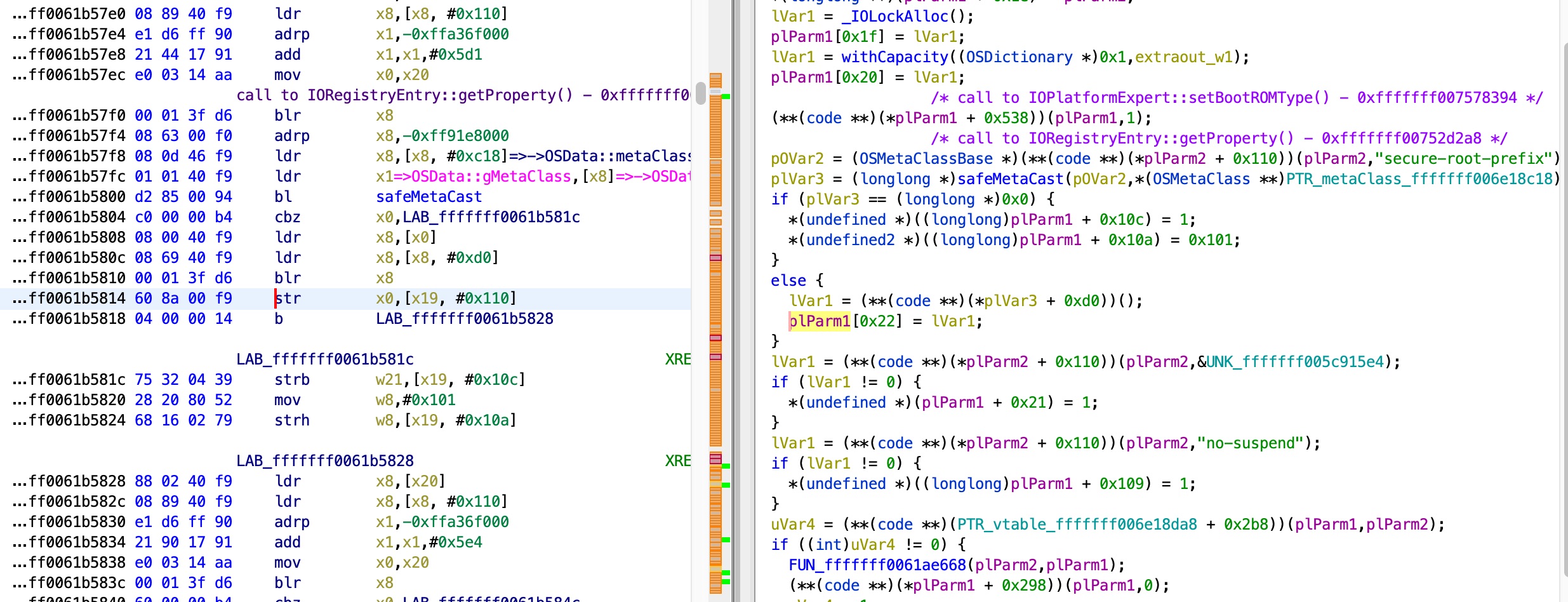
In this function, it is easy to see that when the prop secure-root-prefix is not in the device tree, the member at offset 0x110 is kept untouched with the value 0, and then the original function I looked at (pe->callPlatformFunction()) just returns, and voila - there no need to patch the kernel.
Loading the secure monitor image
Where we left off with the work done by zhuowei, I was able to boot an iPhone X image to user mode. This image boots straight into EL1 and has no secure monitor. I decided to work with another image for iPhone 6s plus, as Apple left off a lot of symbols in there and I thought it would make the research simpler. It turns out that KPP (Kernel Patch Protection) based devices with no KTRR (Kernel Text Readonly Region) have a secure monitor image that needs to be loaded with its own boot args, and executed in EL3. This part of the project was about finding the secure monitor image embedded in the kernel file, loading it, understanding the boot args structure, and loading the image and configuring QEMU to start executing the entry point in EL3. After completing these steps, things still didn’t work. The reason seemed to be that the secure monitor image tries to parse the kernel mach-o header at the kernel base (read from the kernel boot args), and I didn’t have a kernel image at that base address, so it failed with a data-abort. This all happens in this function:
I believe this function is responsible for the KPP functionality because it keeps a map of kernel sections based on the permissions they should have, but this assumption still needs to be verified.
As can be seen in the code from zhuowei, the virt_base arg was pointing to the lowest segment of the loaded kernel:
static uint64_t arm_load_macho(struct arm_boot_info *info, uint64_t *pentry, AddressSpace *as)
{
hwaddr kernel_load_offset = 0x00000000;
hwaddr mem_base = info->loader_start;
uint8_t *data = NULL;
gsize len;
bool ret = false;
uint8_t* rom_buf = NULL;
if (!g_file_get_contents(info->kernel_filename, (char**) &data, &len, NULL)) {
goto out;
}
struct mach_header_64* mh = (struct mach_header_64*)data;
struct load_command* cmd = (struct load_command*)(data + sizeof(struct mach_header_64));
// iterate through all the segments once to find highest and lowest addresses
uint64_t pc = 0;
uint64_t low_addr_temp;
uint64_t high_addr_temp;
macho_highest_lowest(mh, &low_addr_temp, &high_addr_temp);
uint64_t rom_buf_size = high_addr_temp - low_addr_temp;
rom_buf = g_malloc0(rom_buf_size);
for (unsigned int index = 0; index < mh->ncmds; index++) {
switch (cmd->cmd) {
case LC_SEGMENT_64: {
struct segment_command_64* segCmd = (struct segment_command_64*)cmd;
memcpy(rom_buf + (segCmd->vmaddr - low_addr_temp), data + segCmd->fileoff, segCmd->filesize);
break;
}
case LC_UNIXTHREAD: {
// grab just the entry point PC
uint64_t* ptrPc = (uint64_t*)((char*)cmd + 0x110); // for arm64 only.
pc = VAtoPA(*ptrPc);
break;
}
}
cmd = (struct load_command*)((char*)cmd + cmd->cmdsize);
}
hwaddr rom_base = VAtoPA(low_addr_temp);
rom_add_blob_fixed_as("macho", rom_buf, rom_buf_size, rom_base, as);
ret = true;
uint64_t load_extra_offset = high_addr_temp;
uint64_t ramdisk_address = load_extra_offset;
gsize ramdisk_size = 0;
// load ramdisk if exists
if (info->initrd_filename) {
uint8_t* ramdisk_data = NULL;
if (g_file_get_contents(info->initrd_filename, (char**) &ramdisk_data, &ramdisk_size, NULL)) {
info->initrd_filename = NULL;
rom_add_blob_fixed_as("xnu_ramdisk", ramdisk_data, ramdisk_size, VAtoPA(ramdisk_address), as);
load_extra_offset = (load_extra_offset + ramdisk_size + 0xffffull) & ~0xffffull;
g_free(ramdisk_data);
} else {
fprintf(stderr, "ramdisk failed?!\n");
abort();
}
}
uint64_t dtb_address = load_extra_offset;
gsize dtb_size = 0;
// load device tree
if (info->dtb_filename) {
uint8_t* dtb_data = NULL;
if (g_file_get_contents(info->dtb_filename, (char**) &dtb_data, &dtb_size, NULL)) {
info->dtb_filename = NULL;
if (ramdisk_size != 0) {
macho_add_ramdisk_to_dtb(dtb_data, dtb_size, VAtoPA(ramdisk_address), ramdisk_size);
}
rom_add_blob_fixed_as("xnu_dtb", dtb_data, dtb_size, VAtoPA(dtb_address), as);
load_extra_offset = (load_extra_offset + dtb_size + 0xffffull) & ~0xffffull;
g_free(dtb_data);
} else {
fprintf(stderr, "dtb failed?!\n");
abort();
}
}
// fixup boot args
// note: device tree and args must follow kernel and be included in the kernel data size.
// macho_setup_bootargs takes care of adding the size for the args
// osfmk/arm64/arm_vm_init.c:arm_vm_prot_init
uint64_t bootargs_addr = VAtoPA(load_extra_offset);
uint64_t phys_base = (mem_base + kernel_load_offset);
uint64_t virt_base = low_addr_temp & ~0x3fffffffull;
macho_setup_bootargs(info, as, bootargs_addr, virt_base, phys_base, VAtoPA(load_extra_offset), dtb_address, dtb_size);
// write bootloader
uint32_t fixupcontext[FIXUP_MAX];
fixupcontext[FIXUP_ARGPTR] = bootargs_addr;
fixupcontext[FIXUP_ENTRYPOINT] = pc;
write_bootloader("bootloader", info->loader_start,
bootloader_aarch64, fixupcontext, as);
*pentry = info->loader_start;
out:
if (data) {
g_free(data);
}
if (rom_buf) {
g_free(rom_buf);
}
return ret? high_addr_temp - low_addr_temp : -1;
}
This segment, in our case, was mapped below the address of the loaded mach-o header. This means that the virt_base does not point to the kernel mach-o header, and therefore doesn’t work with the secure monitor code as presented above.
One way I tried solving this was by setting the virt_base to the address of the mach-o header, but this made some kernel drivers code load below virt_base, which messed up a lot of stuff, like the following function:
vm_offset_t
ml_static_vtop(vm_offset_t va)
{
for (size_t i = 0; (i < PTOV_TABLE_SIZE) && (ptov_table[i].len != 0); i++) {
if ((va >= ptov_table[i].va) && (va < (ptov_table[i].va + ptov_table[i].len)))
return (va - ptov_table[i].va + ptov_table[i].pa);
}
if (((vm_address_t)(va) - gVirtBase) >= gPhysSize)
panic("ml_static_vtop(): illegal VA: %p\n", (void*)va);
return ((vm_address_t)(va) - gVirtBase + gPhysBase);
}
Another approach I tried was to skip the execution of the secure monitor, and start straight from the kernel entry point in EL1. This worked until I hit the first SMC instruction.
It might have been possible to solve this by patching the kernel at points where SMC is used, but I didn’t want to go this way, as I opted for no patches at all (if possible), and you never know where not having some secure monitor functionality might hit you again.
What eventually worked was setting the virt_base to a lower address below the lowest loaded segment, and just have another copy of the whole raw kernelcache file at this place (in addition to the copy loaded segment by segment where the code is actually executed from).
This solution satisfied all the conditions of having the virt_base below all the virtual addresses actually used in the kernel, having it point to the kernel mach-o header, and having the kernel loaded at its preferred address segment by segment, where it is actually executed from.
Trust Cache
In this section, I will present the work that was done to load non-Apple, self-signed executables. iOS systems normally will only execute trusted executables that are either in a trust cache, or signed by Apple or an installed profile. More background on the subject can be found here, as well as other writeups on the web and in books. In general, there are 3 types of trust caches:
- A trust cache hardcoded in the kernelcache.
- A trust cache that can be loaded at runtime from a file.
- A trust cache in memory pointed to from the device tree.
I decided to go after the 3rd one. The following function contains the top level logic for checking whether an executable has a code signature that is approved for execution, based on trust cahces or otherwise:
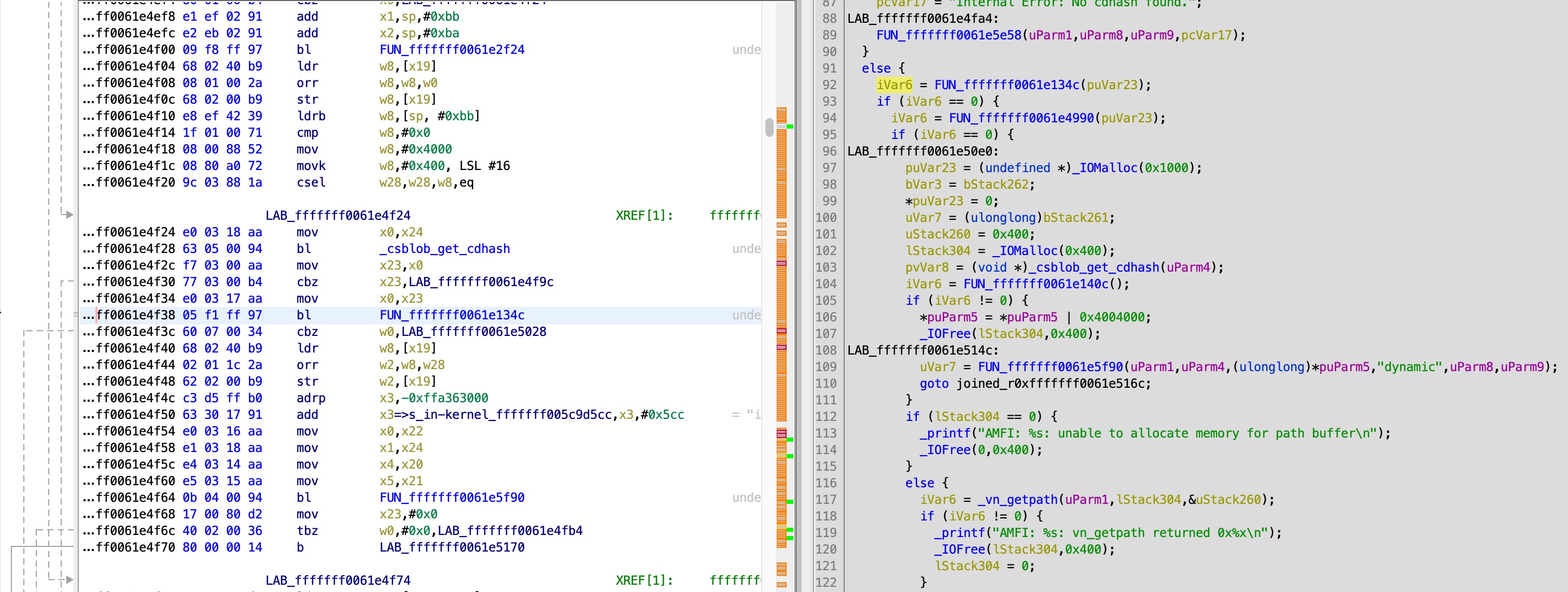
If we drill down deeper, we finally get to this function, that checks the static trust cache:
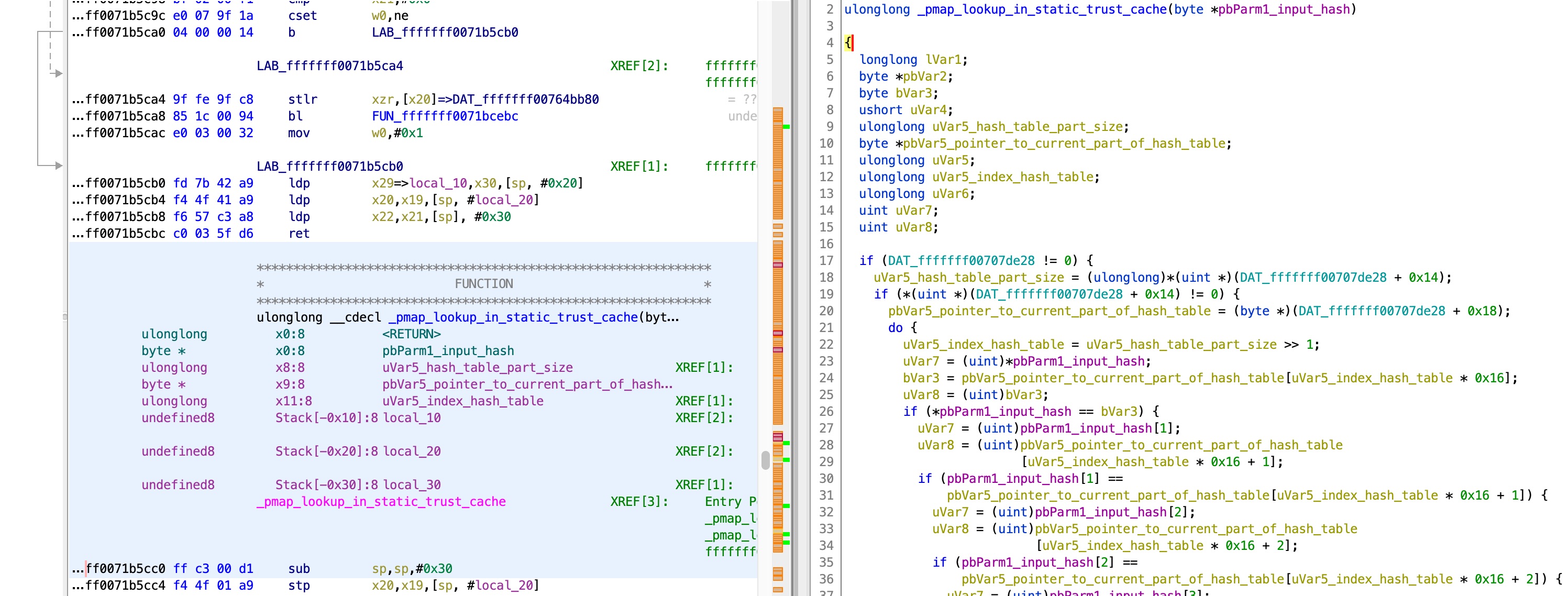
From there, we can see, using XREFs, that the values are set here:
The function above parses the raw trust cache format. It is left as an exercise to the reader to follow the code and the error messages, to conclude that the trust cache format is:
struct cdhash {
uint8_t hash[20]; //first 20 bytes of the cdhash
uint8_t hash_type; //left as 0
uint8_t hash_flags; //left as 0
};
struct static_trust_cache_entry {
uint64_t trust_cache_version; //should be 1
uint64_t unknown1; //left as 0
uint64_t unknown2; //left as 0
uint64_t unknown3; //left as 0
uint64_t unknown4; //left as 0
uint64_t number_of_cdhashes;
struct cdhash[];
};
struct static_trust_cache_buffer {
uint64_t number_of_trust_caches_in_buffer;
uint64_t offsets_to_trust_caches_from_beginning_of_buffer[];
struct static_trust_cache_entry entries[];
};
And it seems that even though the structure supports multiple trust caches in the buffer, the code actually limits the size to 1.
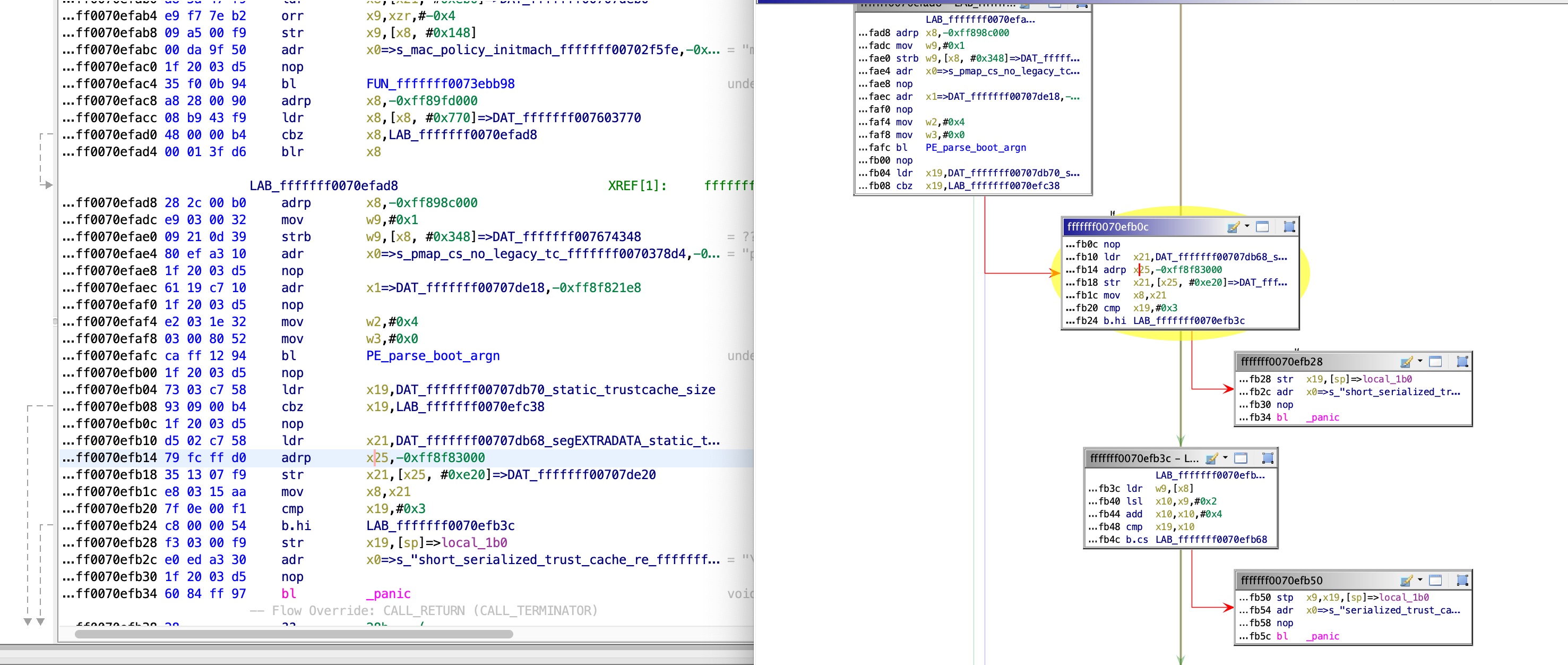
Following XREFS from this function leads us to the following code:
This data is, therefore, read from the device tree.
Now, all that’s left to do is load the trust cache into memory, and point to it from the device tree.
I have to decide where to place it in memory. There is a kernel boot arg top of kernel data which points to the address after the kernel, ramdisk, device tree and the boot args.
The first location I tried was near this top of kernel data address (before and after it).
This didn’t go so well because of the following code which is the code ~matching the above assembly:
void
arm_vm_prot_init(boot_args * args)
{
segLOWESTTEXT = UINT64_MAX;
if (segSizePRELINKTEXT && (segPRELINKTEXTB < segLOWESTTEXT)) segLOWESTTEXT = segPRELINKTEXTB;
assert(segSizeTEXT);
if (segTEXTB < segLOWESTTEXT) segLOWESTTEXT = segTEXTB;
assert(segLOWESTTEXT < UINT64_MAX);
segEXTRADATA = segLOWESTTEXT;
segSizeEXTRADATA = 0;
DTEntry memory_map;
MemoryMapFileInfo *trustCacheRange;
unsigned int trustCacheRangeSize;
int err;
err = DTLookupEntry(NULL, "chosen/memory-map", &memory_map);
assert(err == kSuccess);
err = DTGetProperty(memory_map, "TrustCache", (void**)&trustCacheRange, &trustCacheRangeSize);
if (err == kSuccess) {
assert(trustCacheRangeSize == sizeof(MemoryMapFileInfo));
segEXTRADATA = phystokv(trustCacheRange->paddr);
segSizeEXTRADATA = trustCacheRange->length;
arm_vm_page_granular_RNX(segEXTRADATA, segSizeEXTRADATA, FALSE);
}
/* Map coalesced kext TEXT segment RWNX for now */
arm_vm_page_granular_RWNX(segPRELINKTEXTB, segSizePRELINKTEXT, FALSE); // Refined in OSKext::readPrelinkedExtensions
/* Map coalesced kext DATA_CONST segment RWNX (could be empty) */
arm_vm_page_granular_RWNX(segPLKDATACONSTB, segSizePLKDATACONST, FALSE); // Refined in OSKext::readPrelinkedExtensions
/* Map coalesced kext TEXT_EXEC segment RWX (could be empty) */
arm_vm_page_granular_ROX(segPLKTEXTEXECB, segSizePLKTEXTEXEC, FALSE); // Refined in OSKext::readPrelinkedExtensions
/* if new segments not present, set space between PRELINK_TEXT and xnu TEXT to RWNX
* otherwise we no longer expect any space between the coalesced kext read only segments and xnu rosegments
*/
if (!segSizePLKDATACONST && !segSizePLKTEXTEXEC) {
if (segSizePRELINKTEXT)
arm_vm_page_granular_RWNX(segPRELINKTEXTB + segSizePRELINKTEXT, segTEXTB - (segPRELINKTEXTB + segSizePRELINKTEXT), FALSE);
} else {
/*
* If we have the new segments, we should still protect the gap between kext
* read-only pages and kernel read-only pages, in the event that this gap
* exists.
*/
if ((segPLKDATACONSTB + segSizePLKDATACONST) < segTEXTB) {
arm_vm_page_granular_RWNX(segPLKDATACONSTB + segSizePLKDATACONST, segTEXTB - (segPLKDATACONSTB + segSizePLKDATACONST), FALSE);
}
}
/*
* Protection on kernel text is loose here to allow shenanigans early on. These
* protections are tightened in arm_vm_prot_finalize(). This is necessary because
* we currently patch LowResetVectorBase in cpu.c.
*
* TEXT segment contains mach headers and other non-executable data. This will become RONX later.
*/
arm_vm_page_granular_RNX(segTEXTB, segSizeTEXT, FALSE);
/* Can DATACONST start out and stay RNX?
* NO, stuff in this segment gets modified during startup (viz. mac_policy_init()/mac_policy_list)
* Make RNX in prot_finalize
*/
arm_vm_page_granular_RWNX(segDATACONSTB, segSizeDATACONST, FALSE);
/* TEXTEXEC contains read only executable code: becomes ROX in prot_finalize */
arm_vm_page_granular_RWX(segTEXTEXECB, segSizeTEXTEXEC, FALSE);
/* DATA segment will remain RWNX */
arm_vm_page_granular_RWNX(segDATAB, segSizeDATA, FALSE);
arm_vm_page_granular_RWNX(segBOOTDATAB, segSizeBOOTDATA, TRUE);
arm_vm_page_granular_RNX((vm_offset_t)&intstack_low_guard, PAGE_MAX_SIZE, TRUE);
arm_vm_page_granular_RNX((vm_offset_t)&intstack_high_guard, PAGE_MAX_SIZE, TRUE);
arm_vm_page_granular_RNX((vm_offset_t)&excepstack_high_guard, PAGE_MAX_SIZE, TRUE);
arm_vm_page_granular_ROX(segKLDB, segSizeKLD, FALSE);
arm_vm_page_granular_RWNX(segLINKB, segSizeLINK, FALSE);
arm_vm_page_granular_RWNX(segPLKLINKEDITB, segSizePLKLINKEDIT, FALSE); // Coalesced kext LINKEDIT segment
arm_vm_page_granular_ROX(segLASTB, segSizeLAST, FALSE); // __LAST may be empty, but we cannot assume this
arm_vm_page_granular_RWNX(segPRELINKDATAB, segSizePRELINKDATA, FALSE); // Prelink __DATA for kexts (RW data)
if (segSizePLKLLVMCOV > 0)
arm_vm_page_granular_RWNX(segPLKLLVMCOVB, segSizePLKLLVMCOV, FALSE); // LLVM code coverage data
arm_vm_page_granular_RWNX(segPRELINKINFOB, segSizePRELINKINFO, FALSE); /* PreLinkInfoDictionary */
arm_vm_page_granular_RNX(phystokv(args->topOfKernelData), BOOTSTRAP_TABLE_SIZE, FALSE); // Boot page tables; they should not be mutable.
}
Here we can see that when we have a static trust cache, segEXTRADATA is set to the trust cache buffer, instead of segLOWESTTEXT.
In the following 2 functions we can see that if the data between gVirtBase and segEXTRADATA holds anything meaningful, terrible things happen:
static void
arm_vm_physmap_init(boot_args *args, vm_map_address_t physmap_base, vm_map_address_t dynamic_memory_begin __unused)
{
ptov_table_entry temp_ptov_table[PTOV_TABLE_SIZE];
bzero(temp_ptov_table, sizeof(temp_ptov_table));
// Will be handed back to VM layer through ml_static_mfree() in arm_vm_prot_finalize()
arm_vm_physmap_slide(temp_ptov_table, physmap_base, gVirtBase, segEXTRADATA - gVirtBase, AP_RWNA, FALSE);
arm_vm_page_granular_RWNX(end_kern, phystokv(args->topOfKernelData) - end_kern, FALSE); /* Device Tree, RAM Disk (if present), bootArgs */
arm_vm_physmap_slide(temp_ptov_table, physmap_base, (args->topOfKernelData + BOOTSTRAP_TABLE_SIZE - gPhysBase + gVirtBase),
real_avail_end - (args->topOfKernelData + BOOTSTRAP_TABLE_SIZE), AP_RWNA, FALSE); // rest of physmem
assert((temp_ptov_table[ptov_index - 1].va + temp_ptov_table[ptov_index - 1].len) <= dynamic_memory_begin);
// Sort in descending order of segment length. LUT traversal is linear, so largest (most likely used)
// segments should be placed earliest in the table to optimize lookup performance.
qsort(temp_ptov_table, PTOV_TABLE_SIZE, sizeof(temp_ptov_table[0]), cmp_ptov_entries);
memcpy(ptov_table, temp_ptov_table, sizeof(ptov_table));
}
void
arm_vm_prot_finalize(boot_args * args __unused)
{
/*
* At this point, we are far enough along in the boot process that it will be
* safe to free up all of the memory preceeding the kernel. It may in fact
* be safe to do this earlier.
*
* This keeps the memory in the V-to-P mapping, but advertises it to the VM
* as usable.
*/
/*
* if old style PRELINK segment exists, free memory before it, and after it before XNU text
* otherwise we're dealing with a new style kernel cache, so we should just free the
* memory before PRELINK_TEXT segment, since the rest of the KEXT read only data segments
* should be immediately followed by XNU's TEXT segment
*/
ml_static_mfree(phystokv(gPhysBase), segEXTRADATA - gVirtBase);
/*
* KTRR support means we will be mucking with these pages and trying to
* protect them; we cannot free the pages to the VM if we do this.
*/
if (!segSizePLKDATACONST && !segSizePLKTEXTEXEC && segSizePRELINKTEXT) {
/* If new segments not present, PRELINK_TEXT is not dynamically sized, free DRAM between it and xnu TEXT */
ml_static_mfree(segPRELINKTEXTB + segSizePRELINKTEXT, segTEXTB - (segPRELINKTEXTB + segSizePRELINKTEXT));
}
/*
* LowResetVectorBase patching should be done by now, so tighten executable
* protections.
*/
arm_vm_page_granular_ROX(segTEXTEXECB, segSizeTEXTEXEC, FALSE);
/* tighten permissions on kext read only data and code */
if (segSizePLKDATACONST && segSizePLKTEXTEXEC) {
arm_vm_page_granular_RNX(segPRELINKTEXTB, segSizePRELINKTEXT, FALSE);
arm_vm_page_granular_ROX(segPLKTEXTEXECB, segSizePLKTEXTEXEC, FALSE);
arm_vm_page_granular_RNX(segPLKDATACONSTB, segSizePLKDATACONST, FALSE);
}
cpu_stack_alloc(&BootCpuData);
arm64_replace_bootstack(&BootCpuData);
ml_static_mfree(phystokv(segBOOTDATAB - gVirtBase + gPhysBase), segSizeBOOTDATA);
#if __ARM_KERNEL_PROTECT__
arm_vm_populate_kernel_el0_mappings();
#endif /* __ARM_KERNEL_PROTECT__ */
#if defined(KERNEL_INTEGRITY_KTRR)
/*
* __LAST,__pinst should no longer be executable.
*/
arm_vm_page_granular_RNX(segLASTB, segSizeLAST, FALSE);
/*
* Must wait until all other region permissions are set before locking down DATA_CONST
* as the kernel static page tables live in DATA_CONST on KTRR enabled systems
* and will become immutable.
*/
#endif
arm_vm_page_granular_RNX(segDATACONSTB, segSizeDATACONST, FALSE);
#ifndef __ARM_L1_PTW__
FlushPoC_Dcache();
#endif
__builtin_arm_dsb(DSB_ISH);
flush_mmu_tlb();
}
Alright, so now, based on the above observation, I decided to place the trust cache buffer right after the raw kernel file I placed at virt_base.
This, of course, still didn’t work. Following the code that sets the page table, I found where this memory location gets unloaded from the table, and finally understood that a few pages after the end of the raw kernel file get unloaded from memory at some point. Therefore, I placed it a few MBs above that address, and it finally worked (partially).
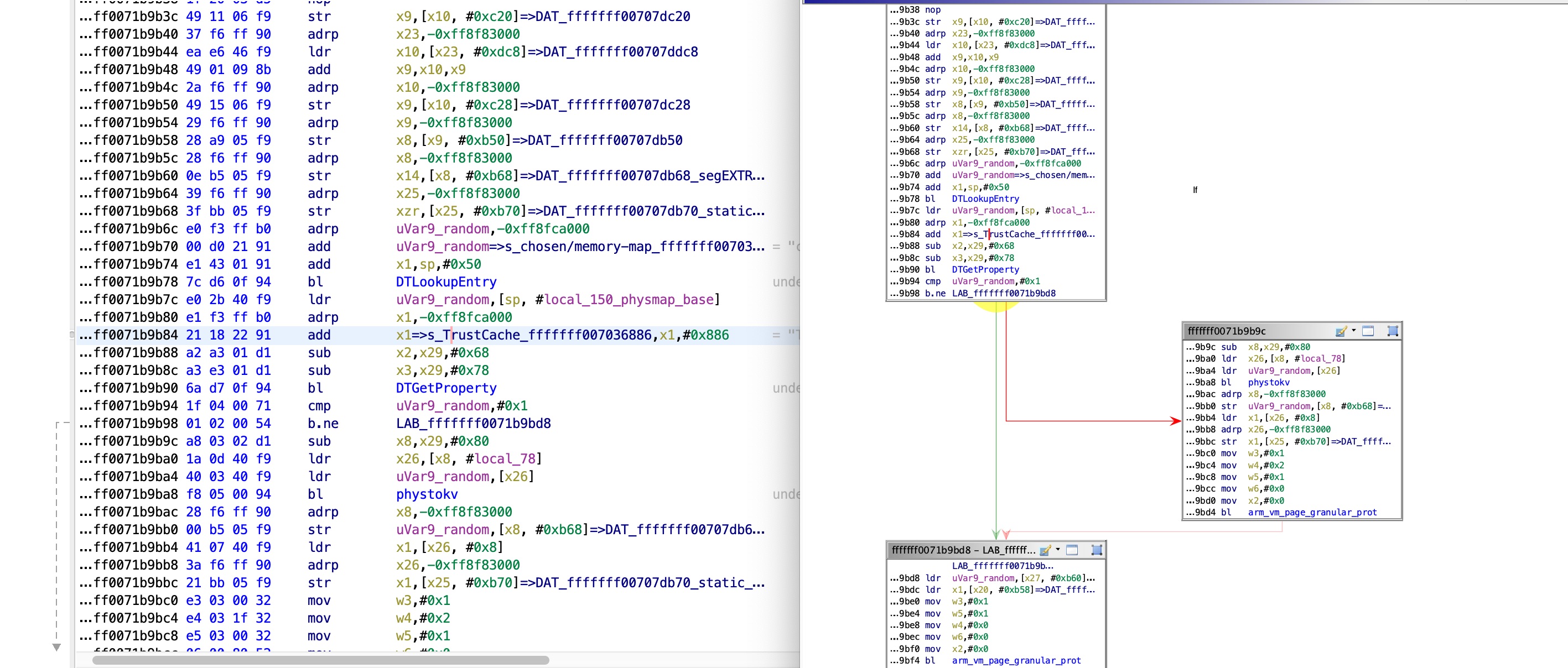
Looking at the code at:
It is left to the reader to read the function and see that a binary search is implemented there. After sorting the hashes in the buffer, it finally worked properly.
Bash launchd item
At this point, I have the ability to execute our own self-signed, non-Apple executables, so I wanted launchd to execute bash instead of the services that exist on the ramdisk. To do so, I deleted all the files in /System/Library/LaunchDaemons/ and added a new file com.apple.bash.plist, with the following content:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE plist PUBLIC "-//Apple//DTD PLIST 1.0//EN" "http://www.apple.com/DTDs/PropertyList-1.0.dtd">
<plist version="1.0">
<dict>
<key>EnablePressuredExit</key>
<false/>
<key>Label</key>
<string>com.apple.bash</string>
<key>POSIXSpawnType</key>
<string>Interactive</string>
<key>ProgramArguments</key>
<array>
<string>/iosbinpack64/bin/bash</string>
</array>
<key>RunAtLoad</key>
<true/>
<key>StandardErrorPath</key>
<string>/dev/console</string>
<key>StandardInPath</key>
<string>/dev/console</string>
<key>StandardOutPath</key>
<string>/dev/console</string>
<key>Umask</key>
<integer>0</integer>
<key>UserName</key>
<string>root</string>
</dict>
</plist>
This made launchd try and execute bash, but still no go. It seems that the ramdisk comes without the dynamic loader cache on it. To solve this, I copied the dyld cache from the full disk image to the ramdisk (after resizing the ramdisk so it would have enough space for it). Alas, it still didn’t work and it seemed the problem was still the same missing libraries, even with the dyld cache in place. To debug this, I needed to better understand where the failure happens. I found out that loading the cache happens inside dyld in:
static void mapSharedCache()
{
uint64_t cacheBaseAddress = 0;
// quick check if a cache is already mapped into shared region
if ( _shared_region_check_np(&cacheBaseAddress) == 0 ) {
sSharedCache = (dyld_cache_header*)cacheBaseAddress;
// if we don't understand the currently mapped shared cache, then ignore
#if __x86_64__
const char* magic = (sHaswell ? ARCH_CACHE_MAGIC_H : ARCH_CACHE_MAGIC);
#else
const char* magic = ARCH_CACHE_MAGIC;
#endif
if ( strcmp(sSharedCache->magic, magic) != 0 ) {
sSharedCache = NULL;
if ( gLinkContext.verboseMapping ) {
dyld::log("dyld: existing shared cached in memory is not compatible\n");
return;
}
}
// check if cache file is slidable
const dyld_cache_header* header = sSharedCache;
if ( (header->mappingOffset >= 0x48) && (header->slideInfoSize != 0) ) {
// solve for slide by comparing loaded address to address of first region
const uint8_t* loadedAddress = (uint8_t*)sSharedCache;
const dyld_cache_mapping_info* const mappings = (dyld_cache_mapping_info*)(loadedAddress+header->mappingOffset);
const uint8_t* preferedLoadAddress = (uint8_t*)(long)(mappings[0].address);
sSharedCacheSlide = loadedAddress - preferedLoadAddress;
dyld::gProcessInfo->sharedCacheSlide = sSharedCacheSlide;
//dyld::log("sSharedCacheSlide=0x%08lX, loadedAddress=%p, preferedLoadAddress=%p\n", sSharedCacheSlide, loadedAddress, preferedLoadAddress);
}
// if cache has a uuid, copy it
if ( header->mappingOffset >= 0x68 ) {
memcpy(dyld::gProcessInfo->sharedCacheUUID, header->uuid, 16);
}
// verbose logging
if ( gLinkContext.verboseMapping ) {
dyld::log("dyld: re-using existing shared cache mapping\n");
}
}
else {
#if __i386__ || __x86_64__
// <rdar://problem/5925940> Safe Boot should disable dyld shared cache
// if we are in safe-boot mode and the cache was not made during this boot cycle,
// delete the cache file
uint32_t safeBootValue = 0;
size_t safeBootValueSize = sizeof(safeBootValue);
if ( (sysctlbyname("kern.safeboot", &safeBootValue, &safeBootValueSize, NULL, 0) == 0) && (safeBootValue != 0) ) {
// user booted machine in safe-boot mode
struct stat dyldCacheStatInfo;
// Don't use custom DYLD_SHARED_CACHE_DIR if provided, use standard path
if ( my_stat(MACOSX_DYLD_SHARED_CACHE_DIR DYLD_SHARED_CACHE_BASE_NAME ARCH_NAME, &dyldCacheStatInfo) == 0 ) {
struct timeval bootTimeValue;
size_t bootTimeValueSize = sizeof(bootTimeValue);
if ( (sysctlbyname("kern.boottime", &bootTimeValue, &bootTimeValueSize, NULL, 0) == 0) && (bootTimeValue.tv_sec != 0) ) {
// if the cache file was created before this boot, then throw it away and let it rebuild itself
if ( dyldCacheStatInfo.st_mtime < bootTimeValue.tv_sec ) {
::unlink(MACOSX_DYLD_SHARED_CACHE_DIR DYLD_SHARED_CACHE_BASE_NAME ARCH_NAME);
gLinkContext.sharedRegionMode = ImageLoader::kDontUseSharedRegion;
return;
}
}
}
}
#endif
// map in shared cache to shared region
int fd = openSharedCacheFile();
if ( fd != -1 ) {
uint8_t firstPages[8192];
if ( ::read(fd, firstPages, 8192) == 8192 ) {
dyld_cache_header* header = (dyld_cache_header*)firstPages;
#if __x86_64__
const char* magic = (sHaswell ? ARCH_CACHE_MAGIC_H : ARCH_CACHE_MAGIC);
#else
const char* magic = ARCH_CACHE_MAGIC;
#endif
if ( strcmp(header->magic, magic) == 0 ) {
const dyld_cache_mapping_info* const fileMappingsStart = (dyld_cache_mapping_info*)&firstPages[header->mappingOffset];
const dyld_cache_mapping_info* const fileMappingsEnd = &fileMappingsStart[header->mappingCount];
shared_file_mapping_np mappings[header->mappingCount+1]; // add room for code-sig
unsigned int mappingCount = header->mappingCount;
int codeSignatureMappingIndex = -1;
int readWriteMappingIndex = -1;
int readOnlyMappingIndex = -1;
// validate that the cache file has not been truncated
bool goodCache = false;
struct stat stat_buf;
if ( fstat(fd, &stat_buf) == 0 ) {
goodCache = true;
int i=0;
for (const dyld_cache_mapping_info* p = fileMappingsStart; p < fileMappingsEnd; ++p, ++i) {
mappings[i].sfm_address = p->address;
mappings[i].sfm_size = p->size;
mappings[i].sfm_file_offset = p->fileOffset;
mappings[i].sfm_max_prot = p->maxProt;
mappings[i].sfm_init_prot = p->initProt;
// rdar://problem/5694507 old update_dyld_shared_cache tool could make a cache file
// that is not page aligned, but otherwise ok.
if ( p->fileOffset+p->size > (uint64_t)(stat_buf.st_size+4095 & (-4096)) ) {
dyld::log("dyld: shared cached file is corrupt: %s" DYLD_SHARED_CACHE_BASE_NAME ARCH_NAME "\n", sSharedCacheDir);
goodCache = false;
}
if ( (mappings[i].sfm_init_prot & (VM_PROT_READ|VM_PROT_WRITE)) == (VM_PROT_READ|VM_PROT_WRITE) ) {
readWriteMappingIndex = i;
}
if ( mappings[i].sfm_init_prot == VM_PROT_READ ) {
readOnlyMappingIndex = i;
}
}
// if shared cache is code signed, add a mapping for the code signature
uint64_t signatureSize = header->codeSignatureSize;
// zero size in header means signature runs to end-of-file
if ( signatureSize == 0 )
signatureSize = stat_buf.st_size - header->codeSignatureOffset;
if ( signatureSize != 0 ) {
int linkeditMapping = mappingCount-1;
codeSignatureMappingIndex = mappingCount++;
mappings[codeSignatureMappingIndex].sfm_address = mappings[linkeditMapping].sfm_address + mappings[linkeditMapping].sfm_size;
#if __arm__ || __arm64__
mappings[codeSignatureMappingIndex].sfm_size = (signatureSize+16383) & (-16384);
#else
mappings[codeSignatureMappingIndex].sfm_size = (signatureSize+4095) & (-4096);
#endif
mappings[codeSignatureMappingIndex].sfm_file_offset = header->codeSignatureOffset;
mappings[codeSignatureMappingIndex].sfm_max_prot = VM_PROT_READ;
mappings[codeSignatureMappingIndex].sfm_init_prot = VM_PROT_READ;
}
}
#if __MAC_OS_X_VERSION_MIN_REQUIRED
// sanity check that /usr/lib/libSystem.B.dylib stat() info matches cache
if ( header->imagesCount * sizeof(dyld_cache_image_info) + header->imagesOffset < 8192 ) {
bool foundLibSystem = false;
if ( my_stat("/usr/lib/libSystem.B.dylib", &stat_buf) == 0 ) {
const dyld_cache_image_info* images = (dyld_cache_image_info*)&firstPages[header->imagesOffset];
const dyld_cache_image_info* const imagesEnd = &images[header->imagesCount];
for (const dyld_cache_image_info* p = images; p < imagesEnd; ++p) {
if ( ((time_t)p->modTime == stat_buf.st_mtime) && ((ino_t)p->inode == stat_buf.st_ino) ) {
foundLibSystem = true;
break;
}
}
}
if ( !sSharedCacheIgnoreInodeAndTimeStamp && !foundLibSystem ) {
dyld::log("dyld: shared cached file was built against a different libSystem.dylib, ignoring cache.\n"
"to update dyld shared cache run: 'sudo update_dyld_shared_cache' then reboot.\n");
goodCache = false;
}
}
#endif
#if __IPHONE_OS_VERSION_MIN_REQUIRED
{
uint64_t lowAddress;
uint64_t highAddress;
getCacheBounds(mappingCount, mappings, lowAddress, highAddress);
if ( (highAddress-lowAddress) > SHARED_REGION_SIZE )
throw "dyld shared cache is too big to fit in shared region";
}
#endif
if ( goodCache && (readWriteMappingIndex == -1) ) {
dyld::log("dyld: shared cached file is missing read/write mapping: %s" DYLD_SHARED_CACHE_BASE_NAME ARCH_NAME "\n", sSharedCacheDir);
goodCache = false;
}
if ( goodCache && (readOnlyMappingIndex == -1) ) {
dyld::log("dyld: shared cached file is missing read-only mapping: %s" DYLD_SHARED_CACHE_BASE_NAME ARCH_NAME "\n", sSharedCacheDir);
goodCache = false;
}
if ( goodCache ) {
long cacheSlide = 0;
void* slideInfo = NULL;
uint64_t slideInfoSize = 0;
// check if shared cache contains slid info
if ( header->slideInfoSize != 0 ) {
// <rdar://problem/8611968> don't slide shared cache if ASLR disabled (main executable didn't slide)
if ( sMainExecutable->isPositionIndependentExecutable() && (sMainExecutable->getSlide() == 0) )
cacheSlide = 0;
else {
// generate random slide amount
cacheSlide = pickCacheSlide(mappingCount, mappings);
slideInfo = (void*)(long)(mappings[readOnlyMappingIndex].sfm_address + (header->slideInfoOffset - mappings[readOnlyMappingIndex].sfm_file_offset));
slideInfoSize = header->slideInfoSize;
// add VM_PROT_SLIDE bit to __DATA area of cache
mappings[readWriteMappingIndex].sfm_max_prot |= VM_PROT_SLIDE;
mappings[readWriteMappingIndex].sfm_init_prot |= VM_PROT_SLIDE;
}
}
if ( gLinkContext.verboseMapping ) {
dyld::log("dyld: calling _shared_region_map_and_slide_np() with regions:\n");
for (int i=0; i < mappingCount; ++i) {
dyld::log(" address=0x%08llX, size=0x%08llX, fileOffset=0x%08llX\n", mappings[i].sfm_address, mappings[i].sfm_size, mappings[i].sfm_file_offset);
}
}
if (_shared_region_map_and_slide_np(fd, mappingCount, mappings, codeSignatureMappingIndex, cacheSlide, slideInfo, slideInfoSize) == 0) {
// successfully mapped cache into shared region
sSharedCache = (dyld_cache_header*)mappings[0].sfm_address;
sSharedCacheSlide = cacheSlide;
dyld::gProcessInfo->sharedCacheSlide = cacheSlide;
//dyld::log("sSharedCache=%p sSharedCacheSlide=0x%08lX\n", sSharedCache, sSharedCacheSlide);
// if cache has a uuid, copy it
if ( header->mappingOffset >= 0x68 ) {
memcpy(dyld::gProcessInfo->sharedCacheUUID, header->uuid, 16);
}
}
else {
#if __IPHONE_OS_VERSION_MIN_REQUIRED
throw "dyld shared cache could not be mapped";
#endif
if ( gLinkContext.verboseMapping )
dyld::log("dyld: shared cached file could not be mapped\n");
}
}
}
else {
if ( gLinkContext.verboseMapping )
dyld::log("dyld: shared cached file is invalid\n");
}
}
else {
if ( gLinkContext.verboseMapping )
dyld::log("dyld: shared cached file cannot be read\n");
}
close(fd);
}
else {
if ( gLinkContext.verboseMapping )
dyld::log("dyld: shared cached file cannot be opened\n");
}
}
// remember if dyld loaded at same address as when cache built
if ( sSharedCache != NULL ) {
gLinkContext.dyldLoadedAtSameAddressNeededBySharedCache = ((uintptr_t)(sSharedCache->dyldBaseAddress) == (uintptr_t)&_mh_dylinker_header);
}
// tell gdb where the shared cache is
if ( sSharedCache != NULL ) {
const dyld_cache_mapping_info* const start = (dyld_cache_mapping_info*)((uint8_t*)sSharedCache + sSharedCache->mappingOffset);
dyld_shared_cache_ranges.sharedRegionsCount = sSharedCache->mappingCount;
// only room to tell gdb about first four regions
if ( dyld_shared_cache_ranges.sharedRegionsCount > 4 )
dyld_shared_cache_ranges.sharedRegionsCount = 4;
const dyld_cache_mapping_info* const end = &start[dyld_shared_cache_ranges.sharedRegionsCount];
int index = 0;
for (const dyld_cache_mapping_info* p = start; p < end; ++p, ++index ) {
dyld_shared_cache_ranges.ranges[index].start = p->address+sSharedCacheSlide;
dyld_shared_cache_ranges.ranges[index].length = p->size;
if ( gLinkContext.verboseMapping ) {
dyld::log(" 0x%08llX->0x%08llX %s%s%s init=%x, max=%x\n",
p->address+sSharedCacheSlide, p->address+sSharedCacheSlide+p->size-1,
((p->initProt & VM_PROT_READ) ? "read " : ""),
((p->initProt & VM_PROT_WRITE) ? "write " : ""),
((p->initProt & VM_PROT_EXECUTE) ? "execute " : ""), p->initProt, p->maxProt);
}
#if __i386__
// If a non-writable and executable region is found in the R/W shared region, then this is __IMPORT segments
// This is an old cache. Make writable. dyld no longer supports turn W on and off as it binds
if ( (p->initProt == (VM_PROT_READ|VM_PROT_EXECUTE)) && ((p->address & 0xF0000000) == 0xA0000000) ) {
if ( p->size != 0 ) {
vm_prot_t prot = VM_PROT_EXECUTE | PROT_READ | VM_PROT_WRITE;
vm_protect(mach_task_self(), p->address, p->size, false, prot);
if ( gLinkContext.verboseMapping ) {
dyld::log("%18s at 0x%08llX->0x%08llX altered permissions to %c%c%c\n", "", p->address,
p->address+p->size-1,
(prot & PROT_READ) ? 'r' : '.', (prot & PROT_WRITE) ? 'w' : '.', (prot & PROT_EXEC) ? 'x' : '.' );
}
}
}
#endif
}
if ( gLinkContext.verboseMapping ) {
// list the code blob
dyld_cache_header* header = (dyld_cache_header*)sSharedCache;
uint64_t signatureSize = header->codeSignatureSize;
// zero size in header means signature runs to end-of-file
if ( signatureSize == 0 ) {
struct stat stat_buf;
// FIXME: need size of cache file actually used
if ( my_stat(IPHONE_DYLD_SHARED_CACHE_DIR DYLD_SHARED_CACHE_BASE_NAME ARCH_NAME, &stat_buf) == 0 )
signatureSize = stat_buf.st_size - header->codeSignatureOffset;
}
if ( signatureSize != 0 ) {
const dyld_cache_mapping_info* const last = &start[dyld_shared_cache_ranges.sharedRegionsCount-1];
uint64_t codeBlobStart = last->address + last->size;
dyld::log(" 0x%08llX->0x%08llX (code signature)\n", codeBlobStart, codeBlobStart+signatureSize);
}
}
#if __IPHONE_OS_VERSION_MIN_REQUIRED
// check for file that enables dyld shared cache dylibs to be overridden
struct stat enableStatBuf;
// check file size to determine if correct file is in place.
// See <rdar://problem/13591370> Need a way to disable roots without removing /S/L/C/com.apple.dyld/enable...
sDylibsOverrideCache = ( (my_stat(IPHONE_DYLD_SHARED_CACHE_DIR "enable-dylibs-to-override-cache", &enableStatBuf) == 0)
&& (enableStatBuf.st_size < ENABLE_DYLIBS_TO_OVERRIDE_CACHE_SIZE) );
#endif
}
}
By using the fun feature from the previous post, which lets us debug user mode apps in the gdb kernel debugger, I was able to debug, by stepping through this function, and seeing what fails.
To do this, I patched dyld with an HLT instruction, which our modified QEMU treats as a breakpoint. I then re-signed the executable with jtool, and added the new signature to the static trust cache:
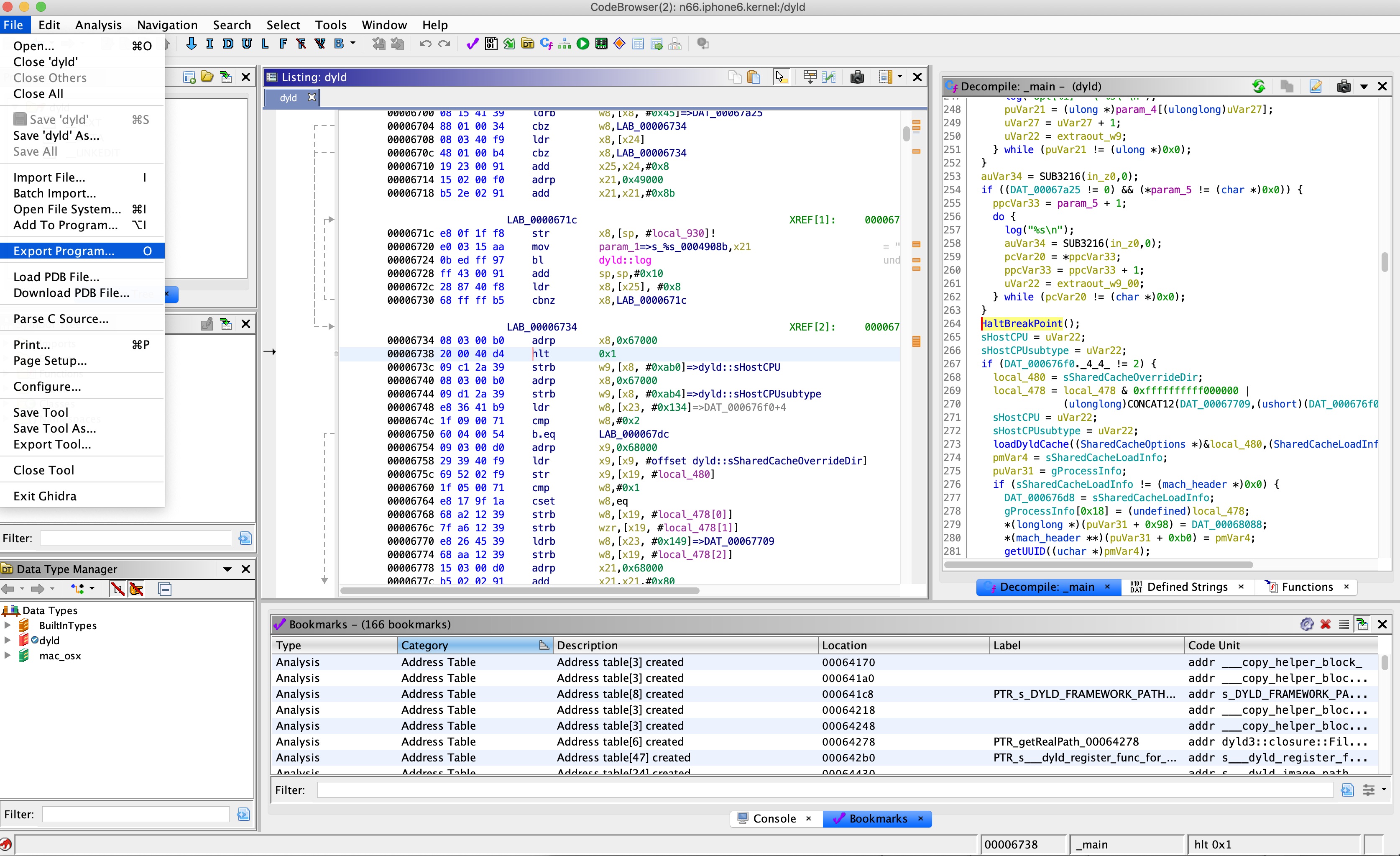
This showed me that actually the failure is in:
if (_shared_region_map_and_slide_np(fd, mappingCount, mappings, codeSignatureMappingIndex, cacheSlide, slideInfo, slideInfoSize) == 0) {
// successfully mapped cache into shared region
sSharedCache = (dyld_cache_header*)mappings[0].sfm_address;
sSharedCacheSlide = cacheSlide;
dyld::gProcessInfo->sharedCacheSlide = cacheSlide;
//dyld::log("sSharedCache=%p sSharedCacheSlide=0x%08lX\n", sSharedCache, sSharedCacheSlide);
// if cache has a uuid, copy it
if ( header->mappingOffset >= 0x68 ) {
memcpy(dyld::gProcessInfo->sharedCacheUUID, header->uuid, 16);
}
}
else {
#if __IPHONE_OS_VERSION_MIN_REQUIRED
throw "dyld shared cache could not be mapped";
#endif
if ( gLinkContext.verboseMapping )
dyld::log("dyld: shared cached file could not be mapped\n");
}
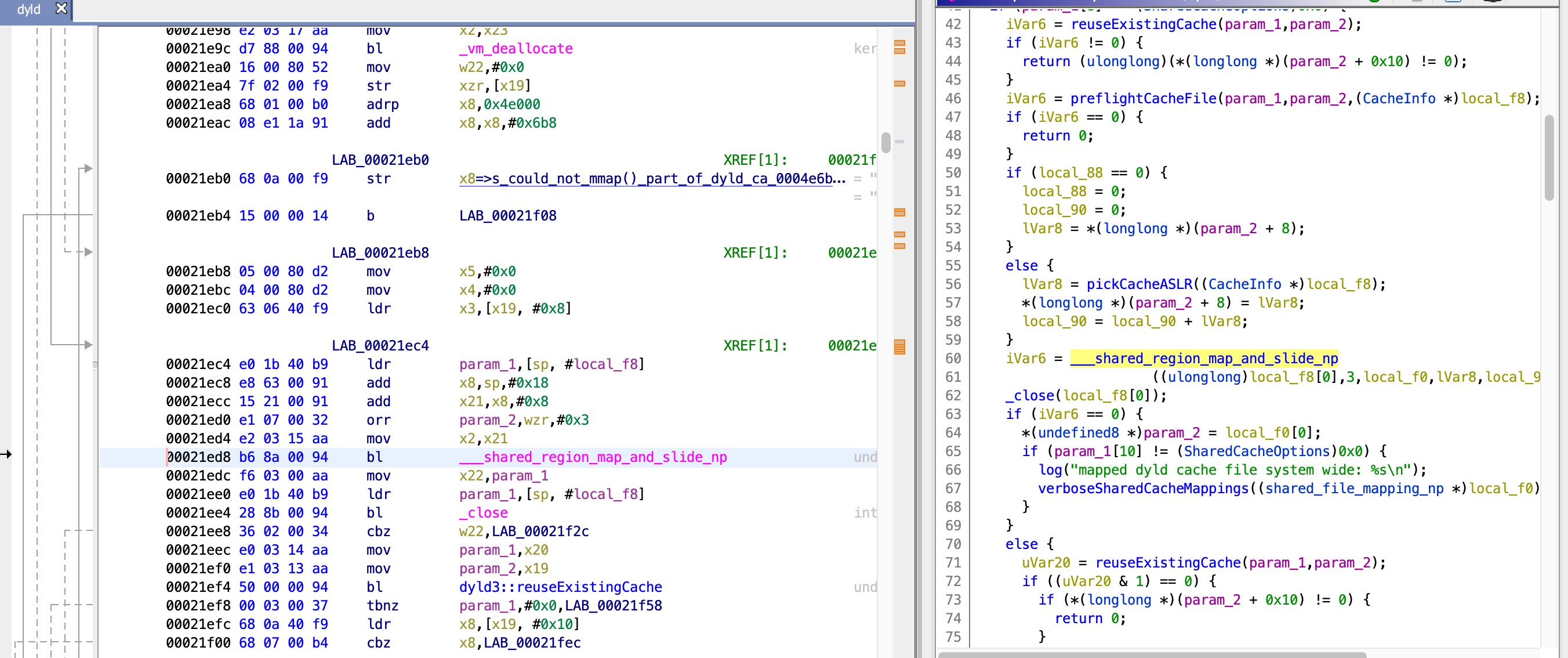
Good thing I am running a kernel debugger, so I can step right into the kernel system call and see where it fails. And another good thing is that I have some version of the code:
int
shared_region_map_and_slide_np(
struct proc *p,
struct shared_region_map_and_slide_np_args *uap,
__unused int *retvalp)
{
struct shared_file_mapping_np *mappings;
unsigned int mappings_count = uap->count;
kern_return_t kr = KERN_SUCCESS;
uint32_t slide = uap->slide;
#define SFM_MAX_STACK 8
struct shared_file_mapping_np stack_mappings[SFM_MAX_STACK];
/* Is the process chrooted?? */
if (p->p_fd->fd_rdir != NULL) {
kr = EINVAL;
goto done;
}
if ((kr = vm_shared_region_sliding_valid(slide)) != KERN_SUCCESS) {
if (kr == KERN_INVALID_ARGUMENT) {
/*
* This will happen if we request sliding again
* with the same slide value that was used earlier
* for the very first sliding.
*/
kr = KERN_SUCCESS;
}
goto done;
}
if (mappings_count == 0) {
SHARED_REGION_TRACE_INFO(
("shared_region: %p [%d(%s)] map(): "
"no mappings\n",
(void *)VM_KERNEL_ADDRPERM(current_thread()),
p->p_pid, p->p_comm));
kr = 0; /* no mappings: we're done ! */
goto done;
} else if (mappings_count <= SFM_MAX_STACK) {
mappings = &stack_mappings[0];
} else {
SHARED_REGION_TRACE_ERROR(
("shared_region: %p [%d(%s)] map(): "
"too many mappings (%d)\n",
(void *)VM_KERNEL_ADDRPERM(current_thread()),
p->p_pid, p->p_comm,
mappings_count));
kr = KERN_FAILURE;
goto done;
}
if ( (kr = shared_region_copyin_mappings(p, uap->mappings, uap->count, mappings))) {
goto done;
}
kr = _shared_region_map_and_slide(p, uap->fd, mappings_count, mappings,
slide,
uap->slide_start, uap->slide_size);
if (kr != KERN_SUCCESS) {
return kr;
}
done:
return kr;
}
By stepping through the code in the debugger, I found that the call to _shared_region_map_and_slide() is what actually fails:
/*
* shared_region_map_np()
*
* This system call is intended for dyld.
*
* dyld uses this to map a shared cache file into a shared region.
* This is usually done only the first time a shared cache is needed.
* Subsequent processes will just use the populated shared region without
* requiring any further setup.
*/
int
_shared_region_map_and_slide(
struct proc *p,
int fd,
uint32_t mappings_count,
struct shared_file_mapping_np *mappings,
uint32_t slide,
user_addr_t slide_start,
user_addr_t slide_size)
{
int error;
kern_return_t kr;
struct fileproc *fp;
struct vnode *vp, *root_vp, *scdir_vp;
struct vnode_attr va;
off_t fs;
memory_object_size_t file_size;
#if CONFIG_MACF
vm_prot_t maxprot = VM_PROT_ALL;
#endif
memory_object_control_t file_control;
struct vm_shared_region *shared_region;
uint32_t i;
SHARED_REGION_TRACE_DEBUG(
("shared_region: %p [%d(%s)] -> map\n",
(void *)VM_KERNEL_ADDRPERM(current_thread()),
p->p_pid, p->p_comm));
shared_region = NULL;
fp = NULL;
vp = NULL;
scdir_vp = NULL;
/* get file structure from file descriptor */
error = fp_lookup(p, fd, &fp, 0);
if (error) {
SHARED_REGION_TRACE_ERROR(
("shared_region: %p [%d(%s)] map: "
"fd=%d lookup failed (error=%d)\n",
(void *)VM_KERNEL_ADDRPERM(current_thread()),
p->p_pid, p->p_comm, fd, error));
goto done;
}
/* make sure we're attempting to map a vnode */
if (FILEGLOB_DTYPE(fp->f_fglob) != DTYPE_VNODE) {
SHARED_REGION_TRACE_ERROR(
("shared_region: %p [%d(%s)] map: "
"fd=%d not a vnode (type=%d)\n",
(void *)VM_KERNEL_ADDRPERM(current_thread()),
p->p_pid, p->p_comm,
fd, FILEGLOB_DTYPE(fp->f_fglob)));
error = EINVAL;
goto done;
}
/* we need at least read permission on the file */
if (! (fp->f_fglob->fg_flag & FREAD)) {
SHARED_REGION_TRACE_ERROR(
("shared_region: %p [%d(%s)] map: "
"fd=%d not readable\n",
(void *)VM_KERNEL_ADDRPERM(current_thread()),
p->p_pid, p->p_comm, fd));
error = EPERM;
goto done;
}
/* get vnode from file structure */
error = vnode_getwithref((vnode_t) fp->f_fglob->fg_data);
if (error) {
SHARED_REGION_TRACE_ERROR(
("shared_region: %p [%d(%s)] map: "
"fd=%d getwithref failed (error=%d)\n",
(void *)VM_KERNEL_ADDRPERM(current_thread()),
p->p_pid, p->p_comm, fd, error));
goto done;
}
vp = (struct vnode *) fp->f_fglob->fg_data;
/* make sure the vnode is a regular file */
if (vp->v_type != VREG) {
SHARED_REGION_TRACE_ERROR(
("shared_region: %p [%d(%s)] map(%p:'%s'): "
"not a file (type=%d)\n",
(void *)VM_KERNEL_ADDRPERM(current_thread()),
p->p_pid, p->p_comm,
(void *)VM_KERNEL_ADDRPERM(vp),
vp->v_name, vp->v_type));
error = EINVAL;
goto done;
}
#if CONFIG_MACF
/* pass in 0 for the offset argument because AMFI does not need the offset
of the shared cache */
error = mac_file_check_mmap(vfs_context_ucred(vfs_context_current()),
fp->f_fglob, VM_PROT_ALL, MAP_FILE, 0, &maxprot);
if (error) {
goto done;
}
#endif /* MAC */
/* make sure vnode is on the process's root volume */
root_vp = p->p_fd->fd_rdir;
if (root_vp == NULL) {
root_vp = rootvnode;
} else {
/*
* Chroot-ed processes can't use the shared_region.
*/
error = EINVAL;
goto done;
}
if (vp->v_mount != root_vp->v_mount) {
SHARED_REGION_TRACE_ERROR(
("shared_region: %p [%d(%s)] map(%p:'%s'): "
"not on process's root volume\n",
(void *)VM_KERNEL_ADDRPERM(current_thread()),
p->p_pid, p->p_comm,
(void *)VM_KERNEL_ADDRPERM(vp), vp->v_name));
error = EPERM;
goto done;
}
/* make sure vnode is owned by "root" */
VATTR_INIT(&va);
VATTR_WANTED(&va, va_uid);
error = vnode_getattr(vp, &va, vfs_context_current());
if (error) {
SHARED_REGION_TRACE_ERROR(
("shared_region: %p [%d(%s)] map(%p:'%s'): "
"vnode_getattr(%p) failed (error=%d)\n",
(void *)VM_KERNEL_ADDRPERM(current_thread()),
p->p_pid, p->p_comm,
(void *)VM_KERNEL_ADDRPERM(vp), vp->v_name,
(void *)VM_KERNEL_ADDRPERM(vp), error));
goto done;
}
if (va.va_uid != 0) {
SHARED_REGION_TRACE_ERROR(
("shared_region: %p [%d(%s)] map(%p:'%s'): "
"owned by uid=%d instead of 0\n",
(void *)VM_KERNEL_ADDRPERM(current_thread()),
p->p_pid, p->p_comm,
(void *)VM_KERNEL_ADDRPERM(vp),
vp->v_name, va.va_uid));
error = EPERM;
goto done;
}
if (scdir_enforce) {
/* get vnode for scdir_path */
error = vnode_lookup(scdir_path, 0, &scdir_vp, vfs_context_current());
if (error) {
SHARED_REGION_TRACE_ERROR(
("shared_region: %p [%d(%s)] map(%p:'%s'): "
"vnode_lookup(%s) failed (error=%d)\n",
(void *)VM_KERNEL_ADDRPERM(current_thread()),
p->p_pid, p->p_comm,
(void *)VM_KERNEL_ADDRPERM(vp), vp->v_name,
scdir_path, error));
goto done;
}
/* ensure parent is scdir_vp */
if (vnode_parent(vp) != scdir_vp) {
SHARED_REGION_TRACE_ERROR(
("shared_region: %p [%d(%s)] map(%p:'%s'): "
"shared cache file not in %s\n",
(void *)VM_KERNEL_ADDRPERM(current_thread()),
p->p_pid, p->p_comm,
(void *)VM_KERNEL_ADDRPERM(vp),
vp->v_name, scdir_path));
error = EPERM;
goto done;
}
}
/* get vnode size */
error = vnode_size(vp, &fs, vfs_context_current());
if (error) {
SHARED_REGION_TRACE_ERROR(
("shared_region: %p [%d(%s)] map(%p:'%s'): "
"vnode_size(%p) failed (error=%d)\n",
(void *)VM_KERNEL_ADDRPERM(current_thread()),
p->p_pid, p->p_comm,
(void *)VM_KERNEL_ADDRPERM(vp), vp->v_name,
(void *)VM_KERNEL_ADDRPERM(vp), error));
goto done;
}
file_size = fs;
/* get the file's memory object handle */
file_control = ubc_getobject(vp, UBC_HOLDOBJECT);
if (file_control == MEMORY_OBJECT_CONTROL_NULL) {
SHARED_REGION_TRACE_ERROR(
("shared_region: %p [%d(%s)] map(%p:'%s'): "
"no memory object\n",
(void *)VM_KERNEL_ADDRPERM(current_thread()),
p->p_pid, p->p_comm,
(void *)VM_KERNEL_ADDRPERM(vp), vp->v_name));
error = EINVAL;
goto done;
}
/* check that the mappings are properly covered by code signatures */
if (!cs_system_enforcement()) {
/* code signing is not enforced: no need to check */
} else for (i = 0; i < mappings_count; i++) {
if (mappings[i].sfm_init_prot & VM_PROT_ZF) {
/* zero-filled mapping: not backed by the file */
continue;
}
if (ubc_cs_is_range_codesigned(vp,
mappings[i].sfm_file_offset,
mappings[i].sfm_size)) {
/* this mapping is fully covered by code signatures */
continue;
}
SHARED_REGION_TRACE_ERROR(
("shared_region: %p [%d(%s)] map(%p:'%s'): "
"mapping #%d/%d [0x%llx:0x%llx:0x%llx:0x%x:0x%x] "
"is not code-signed\n",
(void *)VM_KERNEL_ADDRPERM(current_thread()),
p->p_pid, p->p_comm,
(void *)VM_KERNEL_ADDRPERM(vp), vp->v_name,
i, mappings_count,
mappings[i].sfm_address,
mappings[i].sfm_size,
mappings[i].sfm_file_offset,
mappings[i].sfm_max_prot,
mappings[i].sfm_init_prot));
error = EINVAL;
goto done;
}
/* get the process's shared region (setup in vm_map_exec()) */
shared_region = vm_shared_region_trim_and_get(current_task());
if (shared_region == NULL) {
SHARED_REGION_TRACE_ERROR(
("shared_region: %p [%d(%s)] map(%p:'%s'): "
"no shared region\n",
(void *)VM_KERNEL_ADDRPERM(current_thread()),
p->p_pid, p->p_comm,
(void *)VM_KERNEL_ADDRPERM(vp), vp->v_name));
error = EINVAL;
goto done;
}
/* map the file into that shared region's submap */
kr = vm_shared_region_map_file(shared_region,
mappings_count,
mappings,
file_control,
file_size,
(void *) p->p_fd->fd_rdir,
slide,
slide_start,
slide_size);
if (kr != KERN_SUCCESS) {
SHARED_REGION_TRACE_ERROR(
("shared_region: %p [%d(%s)] map(%p:'%s'): "
"vm_shared_region_map_file() failed kr=0x%x\n",
(void *)VM_KERNEL_ADDRPERM(current_thread()),
p->p_pid, p->p_comm,
(void *)VM_KERNEL_ADDRPERM(vp), vp->v_name, kr));
switch (kr) {
case KERN_INVALID_ADDRESS:
error = EFAULT;
break;
case KERN_PROTECTION_FAILURE:
error = EPERM;
break;
case KERN_NO_SPACE:
error = ENOMEM;
break;
case KERN_FAILURE:
case KERN_INVALID_ARGUMENT:
default:
error = EINVAL;
break;
}
goto done;
}
error = 0;
vnode_lock_spin(vp);
vp->v_flag |= VSHARED_DYLD;
vnode_unlock(vp);
/* update the vnode's access time */
if (! (vnode_vfsvisflags(vp) & MNT_NOATIME)) {
VATTR_INIT(&va);
nanotime(&va.va_access_time);
VATTR_SET_ACTIVE(&va, va_access_time);
vnode_setattr(vp, &va, vfs_context_current());
}
if (p->p_flag & P_NOSHLIB) {
/* signal that this process is now using split libraries */
OSBitAndAtomic(~((uint32_t)P_NOSHLIB), &p->p_flag);
}
done:
if (vp != NULL) {
/*
* release the vnode...
* ubc_map() still holds it for us in the non-error case
*/
(void) vnode_put(vp);
vp = NULL;
}
if (fp != NULL) {
/* release the file descriptor */
fp_drop(p, fd, fp, 0);
fp = NULL;
}
if (scdir_vp != NULL) {
(void)vnode_put(scdir_vp);
scdir_vp = NULL;
}
if (shared_region != NULL) {
vm_shared_region_deallocate(shared_region);
}
SHARED_REGION_TRACE_DEBUG(
("shared_region: %p [%d(%s)] <- map\n",
(void *)VM_KERNEL_ADDRPERM(current_thread()),
p->p_pid, p->p_comm));
return error;
}
And by stepping through this function in the kernel debugger, I found that the failure is in this part:
/* make sure vnode is owned by "root" */
VATTR_INIT(&va);
VATTR_WANTED(&va, va_uid);
error = vnode_getattr(vp, &va, vfs_context_current());
if (error) {
SHARED_REGION_TRACE_ERROR(
("shared_region: %p [%d(%s)] map(%p:'%s'): "
"vnode_getattr(%p) failed (error=%d)\n",
(void *)VM_KERNEL_ADDRPERM(current_thread()),
p->p_pid, p->p_comm,
(void *)VM_KERNEL_ADDRPERM(vp), vp->v_name,
(void *)VM_KERNEL_ADDRPERM(vp), error));
goto done;
}
if (va.va_uid != 0) {
SHARED_REGION_TRACE_ERROR(
("shared_region: %p [%d(%s)] map(%p:'%s'): "
"owned by uid=%d instead of 0\n",
(void *)VM_KERNEL_ADDRPERM(current_thread()),
p->p_pid, p->p_comm,
(void *)VM_KERNEL_ADDRPERM(vp),
vp->v_name, va.va_uid));
error = EPERM;
goto done;
}
And the problem is that the cache file isn’t owned by root, so I found a way to mount the ramdisk on OSX with file permissions enabled, and chowned the file.
This made bash work! Now we only have stdout, but no input support.
UART interactive I/O
Now, all that’s left is enabling UART input. After going over and reversing some of the serial I/O handling code I found this place, which decides whether to enable the UART input (which is off by default):
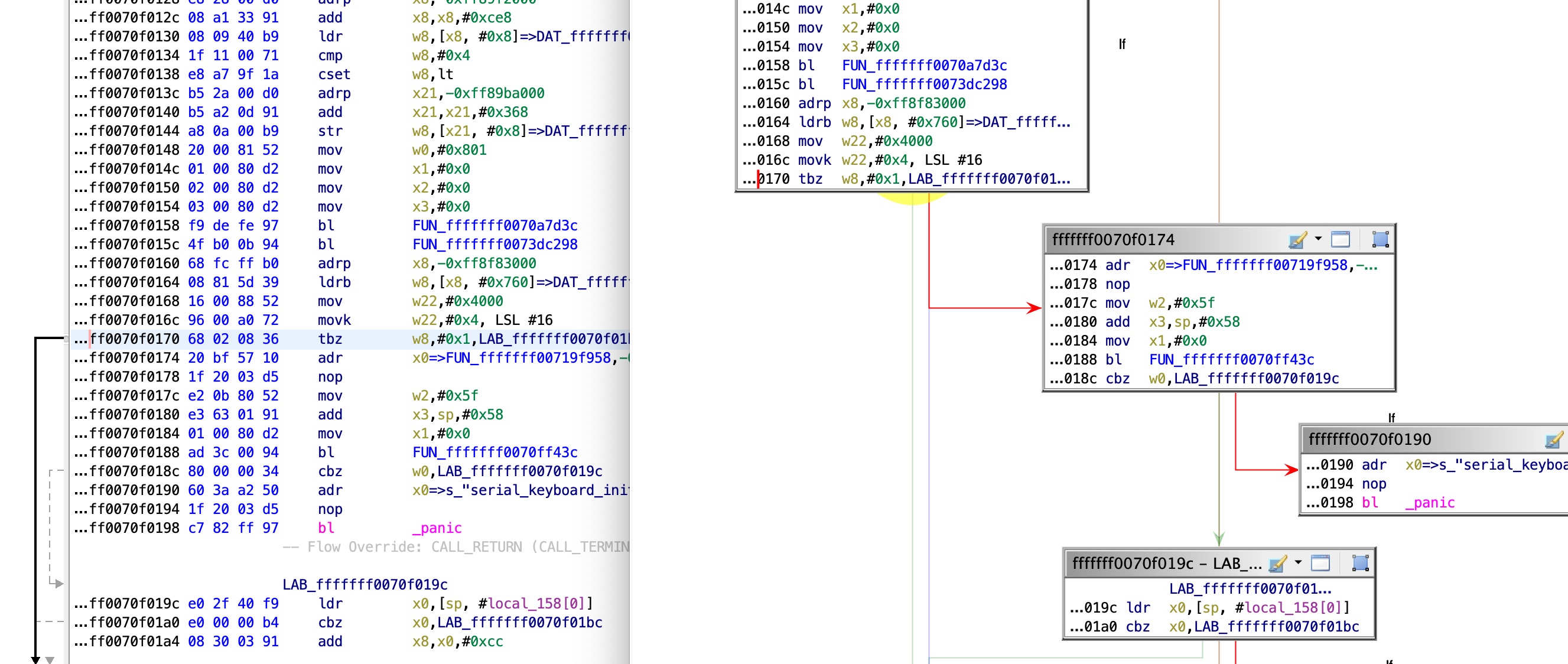
This code reads a global value, and checks bit #1. If it is on, UART input is enabled. By examining this global, we can see that it is set here:
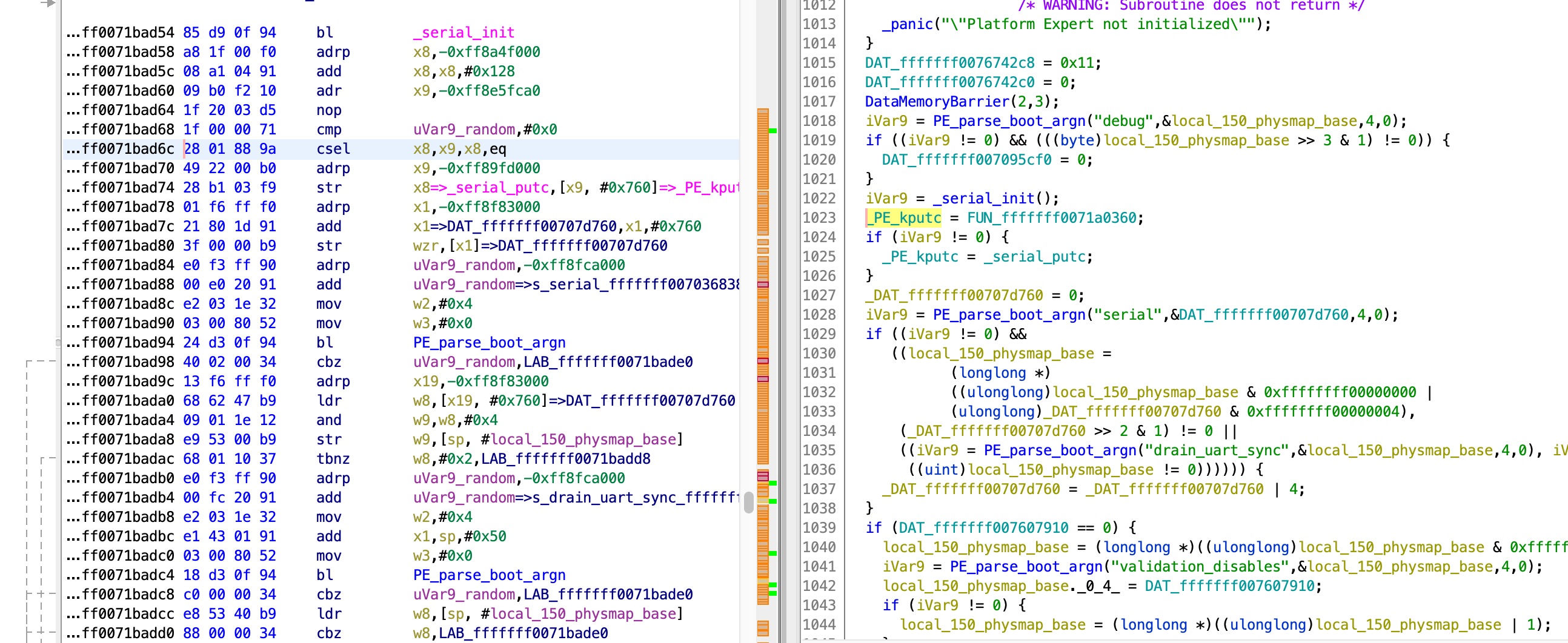
The value is taken from the serial boot arg. So finally, by setting the serial boot arg to 2 (bit #1 on) I got an interactive bash shell!
Conclusion
This project was a lot of fun and the team plans to keep working on it and expand the features mentioned in the previous post. This post shows some of the details of some of the interesting parts of the work, but as I worked very sparsely on this project for the past few months, and documentation during the research lacked some details, not all the details are here. With that in mind, all the functionality is in the code which does include comments in non-trivial places. I got into iOS internals only through this project, so some parts can possibly be improved, and I already received some improvement suggestions. If you have any comments/ideas/suggestions for this project, please comment and/or contact me.